Exploring Global Development Patterns with World Bank Data
An exploratory data analysis using Stata to investigate GDP, literacy rates, and mortality indicators across countries
stata
development-economics
regression
Author
Nadhira A. Hendra
Published
January 12, 2026
Modified
January 13, 2026
Introduction
This analysis started as one of my class assignment. The task was to explore World Bank development indicators, how GDP per capita relates to literacy rates, infant mortality, and income inequality across countries.
In my previous role at Traveloka, most of my analytical work centered on SQL and Python. For this project, I wanted to demonstrate my statistical analysis capabilities using Stata, focusing on regression techniques and econometric approaches to understanding development patterns.
I hope this serves as both a personal reference and a resource for others working with similar datasets.
Problem
The key questions we’re trying to answer in this analysis is:
How unequal is global income distribution?
What patterns emerge when comparing the richest and poorest countries?
Can simple regression models capture the relationships between income, education, and health?
Exploratory Analysis
Setup
To Setup stata in R, we use Statamarkdown library. It is a free open-source R package available on CRAN and Github. However, while the package is free, we still need to have Stata installed in the computer for the library to function. At the moment of making this article I have the Basic one (StataBE) in my computer.
As you can see below I add an engine.path in which this specify the location of the App. Since my Stata is in the application folder, knitr wouldn’t find it automatically and Stata could fail to execute. When the setup is done, we can continue with data preparation!
library(Statamarkdown)
Stata found at /Applications/StataNow/StataBE.app/Contents/MacOS/StataBE
The World Bank Development Indicators dataset contains panel data spanning 2015-2024, the data itself can be obtain from this website here World Bank DataBank. The raw data requires substantial amount of cleaning before we can explore further
Code
clear/* a) Import CSV with proper variable types */import delimited "wb_indicators_2015_2024.csv", varnames(1) /// numericcols(5 6 7 8 9 10 11 12 13 14)/* b) Examine initial data structure. */describe/* c) Generate row id and remove regional aggregates. Upon eyeballing the data we observe that entries after row 1085 are regional/world aggregates */generate id = _nkeepif id < 1086/* d) Reshape from wide to long format and use the column name as the value for yr */reshapelong yr, i(id) j(year)rename yr seriesvalue/* e) Since we found several countries with some years that have null indicator, we further clean the data by keeping most recent non-missing value per country-indicator */gsort countrycode seriescode -yearkeepif seriesvalue < .gsort seriescode seriesname countrycode countryname -yearby seriescode seriesname countrycode countryname: keepif_n == 1sort countryname seriescode* Save cleaned long-formatdatasave"wb_cleaned_long.dta", replace
(encoding automatically selected: ISO-8859-1)
(14 vars, 1,330 obs)
Contains data
Observations: 1,330
Variables: 14
-------------------------------------------------------------------------------------------
Variable Storage Display Value
name type format label Variable label
-------------------------------------------------------------------------------------------
countryname str73 %73s Country Name
countrycode str3 %9s Country Code
seriesname str60 %60s Series Name
seriescode str17 %17s Series Code
yr2015 float %8.0g 2015 [YR2015]
yr2016 float %8.0g 2016 [YR2016]
yr2017 float %8.0g 2017 [YR2017]
yr2018 float %8.0g 2018 [YR2018]
yr2019 float %8.0g 2019 [YR2019]
yr2020 float %8.0g 2020 [YR2020]
yr2021 float %8.0g 2021 [YR2021]
yr2022 float %8.0g 2022 [YR2022]
yr2023 float %8.0g 2023 [YR2023]
yr2024 float %8.0g 2024 [YR2024]
-------------------------------------------------------------------------------------------
Sorted by:
Note: Dataset has changed since last saved.
(245 observations deleted)
(j = 2015 2016 2017 2018 2019 2020 2021 2022 2023 2024)
Data Wide -> Long
-----------------------------------------------------------------------------
Number of observations 1,085 -> 10,850
Number of variables 15 -> 7
j variable (10 values) -> year
xij variables:
yr2015 yr2016 ... yr2024 -> yr
-----------------------------------------------------------------------------
(5,937 observations deleted)
(4,063 observations deleted)
file wb_cleaned_long.dta saved
Descriptive Statistics by indicator
With the cleaned data, we now can examine the distribution of each development indicator across countries. Since the nature of the library (it cannot save last data transformation between chunks), we need to load the dataset everytime we wanted to explore and save the data after we made changes in the data.
-> seriesname = GDP per capita (current US$)
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
seriesvalue | 212 22654.69 33300.99 153.9302 256580.5
-------------------------------------------------------------------------------------------
-> seriesname = Literacy rate, adult female (% of fema..
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
seriesvalue | 152 82.10739 21.35883 18.87 100
-------------------------------------------------------------------------------------------
-> seriesname = Literacy rate, adult male (% of males ..
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
seriesvalue | 145 87.76561 15.06481 35.78 100
-------------------------------------------------------------------------------------------
-> seriesname = Literacy rate, adult total (% of peopl..
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
seriesvalue | 145 84.76617 18.2601 27.28 100
-------------------------------------------------------------------------------------------
-> seriesname = Mortality rate, infant (per 1,000 live..
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
seriesvalue | 196 18.76224 16.70753 1.4 72.6
The summary statistics reveal variation across all indicators. GDP per capita ranges from under $300 to over $100,000, while literacy rates span from 27% to nearly 100%. This indicates that there’s wide gap between literacy rate among low and high income countries
Reshape to look deeper into the indicators
To analyze relationships between indicators, we need to reshape the data to wide format where each country is one observation with separate columns for each indicator. We also will replace some series code so that it is more intepretable by the readers.
Code
* Load cleaned datause"wb_cleaned_long.dta", clear* Rename series codes for readabilityreplace seriescode = "gdp"if seriescode == "NY.GDP.PCAP.CD"replace seriescode = "female_literacy"if seriescode == "SE.ADT.LITR.FE.ZS"replace seriescode = "male_literacy"if seriescode == "SE.ADT.LITR.MA.ZS"replace seriescode = "adult_literacy"if seriescode == "SE.ADT.LITR.ZS"replace seriescode = "mortality"if seriescode == "SP.DYN.IMRT.IN"* Drop unnecessary variables and reshapewidedrop id year seriesnamereshapewide seriesvalue, i(countrycode countryname) j(seriescode) string* Rename variables for clarityrename seriesvaluegdp gdprename seriesvaluefemale_literacy female_literacyrename seriesvaluemale_literacy male_literacyrename seriesvalueadult_literacy adult_literacyrename seriesvaluemortality mortality* Save wide-formatdatafor analysissave"wb_cleaned_wide.dta", replacedescribe
(212 real changes made)
(152 real changes made)
(145 real changes made)
(145 real changes made)
(196 real changes made)
(j = adult_literacy female_literacy gdp male_literacy mortality)
Data Long -> Wide
-----------------------------------------------------------------------------
Number of observations 850 -> 216
Number of variables 4 -> 7
j variable (5 values) seriescode -> (dropped)
xij variables:
seriesvalue -> seriesvalueadult_literacy seriesvaluefemale_
> literacy ... seriesvaluemortality
-----------------------------------------------------------------------------
file wb_cleaned_wide.dta saved
Contains data from wb_cleaned_wide.dta
Observations: 216
Variables: 7 13 Jan 2026 23:26
-------------------------------------------------------------------------------------------
Variable Storage Display Value
name type format label Variable label
-------------------------------------------------------------------------------------------
countrycode str3 %9s Country Code
countryname str73 %73s Country Name
adult_literacy float %8.0g adult_literacy seriesvalue
female_literacy float %8.0g female_literacy seriesvalue
gdp float %8.0g gdp seriesvalue
male_literacy float %8.0g male_literacy seriesvalue
mortality float %8.0g mortality seriesvalue
-------------------------------------------------------------------------------------------
Sorted by: countrycode countryname
Comparing Rich and Poor Countries
One of the way to make the difference obvious between countries to show how severe the inequality is by comparing development outcomes between the richest and poorest countries by GDP per capita. In the table below we will compare the literacy and mortality across top 50 and bottom 50 countries
Code
* Load wide-formatdatause"wb_cleaned_wide.dta", clear* Top 50 countries by GDP per capitadisplay"=== TOP 50 COUNTRIES BY GDP PER CAPITA ==="gsort -gdpsummarize adult_literacy female_literacy male_literacy mortality in 1/50* Bottom 50 countries by GDP per capitadisplay""display"=== BOTTOM 50 COUNTRIES BY GDP PER CAPITA ==="sort gdpsummarize adult_literacy female_literacy male_literacy mortality in 1/50
=== TOP 50 COUNTRIES BY GDP PER CAPITA ===
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
adult_lite~y | 14 97.79929 1.973078 92.4 100
female_lit~y | 14 97.365 1.95109 92.4 100
male_liter~y | 14 98.09429 2.25755 92.4 100
mortality | 35 3.451429 1.937763 1.4 11.4
=== BOTTOM 50 COUNTRIES BY GDP PER CAPITA ===
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
adult_lite~y | 47 65.98271 19.28016 27.28 99.6
female_lit~y | 49 60.33596 22.55905 18.87 99.5
male_liter~y | 47 72.53659 16.63416 35.78 99.7
mortality | 50 39.714 14.24526 14.3 72.6
The gap is striking for infant mortality, the highest mortality rate among wealthy countries (11.4 death per 1000 live births) is lower than the lowest rate among poor countries (14.3 death per 1000 live births). It indicates a wide gap and systemic differences in health infrastructure.
Distribution Analysis
The distribution of GDP per capita reveals important insights about global inequality. The median ($8536) is much lower than the Mean ($22654) which indicates there’s more low income countries globally
Code
* Load wide-formatdatause"wb_cleaned_wide.dta", clear* Detailed distribution statisticssummarize gdp, detail
gdp seriesvalue
-------------------------------------------------------------
Percentiles Smallest
1% 433.174 153.9302
5% 806.9457 413.7579
10% 1016.089 433.174 Obs 212
25% 2703.279 508.3713 Sum of wgt. 212
50% 8536.106 Mean 22654.69
Largest Std. dev. 33300.99
75% 31438.36 137516.6
90% 56833.2 138935 Variance 1.11e+09
95% 85809.9 207973.6 Skewness 3.302677
99% 138935 256580.5 Kurtosis 18.64592
Regression Analysis
TipCorrelation vs. Causation
In this document, with the correlational relationships that is present, we cannot claim that increasing GDP would cause mortality to fall. Reason is because in data without randomization presents, there could be reverse causality (e.g Lower mortality might cause countries to grow faster instead of Rich countries might cause lower mortality rates), or omitted variables (e.g like institutional quality could drive both mortality and gdp). To reduce this possibility we would require randomization or quasi-experimental methods like Regression Discontinuity Design or Instrumental Variables. Hence all the interpretation here is not causal
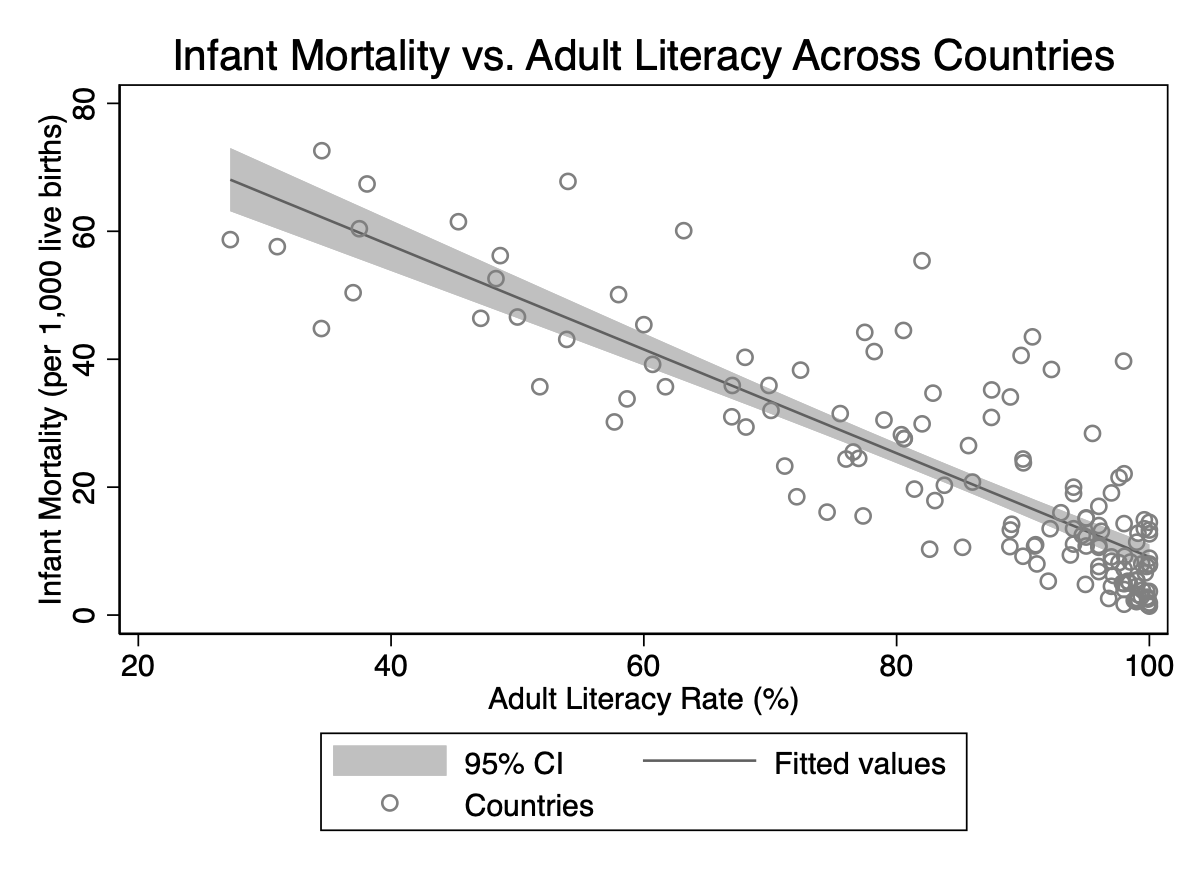
Infant Mortality on GDP Per Capita
Code
* Load wide-formatdatause"wb_cleaned_wide.dta", clear* Regression: infant mortality on GDP per capitaregress mortality gdp
Source | SS df MS Number of obs = 192
-------------+---------------------------------- F(1, 190) = 56.73
Model | 12487.5383 1 12487.5383 Prob > F = 0.0000
Residual | 41822.6659 190 220.119294 R-squared = 0.2299
-------------+---------------------------------- Adj R-squared = 0.2259
Total | 54310.2041 191 284.346619 Root MSE = 14.836
------------------------------------------------------------------------------
mortality | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
gdp | -.000278 .0000369 -7.53 0.000 -.0003508 -.0002052
_cons | 23.98073 1.274607 18.81 0.000 21.46654 26.49493
------------------------------------------------------------------------------
Each additional $1,000 in GDP per capita is associated with approximately 0.27 fewer infant deaths per 1,000 live births. The negative coefficient aligns with expectations: wealthier countries typically have better healthcare infrastructure. And the difference is statistically significant with p-value < 0.05
Literacy on GDP Per Capita
Code
* Load wide-formatdatause"wb_cleaned_wide.dta", clear* Regression: adult literacy on GDP per capitaregress adult_literacy gdp
Source | SS df MS Number of obs = 142
-------------+---------------------------------- F(1, 140) = 33.03
Model | 9077.13217 1 9077.13217 Prob > F = 0.0000
Residual | 38470.2731 140 274.787665 R-squared = 0.1909
-------------+---------------------------------- Adj R-squared = 0.1851
Total | 47547.4053 141 337.21564 Root MSE = 16.577
------------------------------------------------------------------------------
adult_lite~y | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
gdp | .0004964 .0000864 5.75 0.000 .0003256 .0006672
_cons | 78.89866 1.711204 46.11 0.000 75.51552 82.28181
------------------------------------------------------------------------------
Higher GDP is associated with higher literacy rates, though the relationship is modest in magnitude. Each additional $1000 increase GDP is associated with increases in adult literacy by 0.04.
The persistent gap between male and female literacy rates reflects socio-cultural norms in many low- and middle-income countries that historically prioritized boys’ education.
Conclusion
The exploratory analysis reveals pattern that gap between the richest and poorest countries isn’t just about income but also manifest in infant survival rates, literacy and gender disparities in education. The correlations here can’t tell us whether raising GDP would improve health outcomes or whether causal relationships exist between these indicators. Still, exploratory analysis like this can generate hypotheses worth testing with quasi-experimental or experimental methods in future work. On a practical note, I found Stata’s syntax efficient for this kind of work. Reshaping and regression tale just a view line of code. I hope this serve as a useful reference for data exploration using Stata